MySQL 可以恢复到半个月内任意一秒的状态,这个是如何做到的?
首先列举一下 mysql 中的日志。
- 错误日志(error log):故名思意,记录错误信息,启动信息等。
- 查询日志(general log):记录与客户端连接和执行的语句(基本不用)。
- 二进制日志(bin log):记录对数据库的修改操作,恢复到之前的状态也是通过 bin log + 表的备份完成的。
- 慢查询日志(slow log):经常遇到的问题,记录所有执行时间超过 long_query_time 的所有查询或不使用索引的查询。
- 中继日志(relay log):主从复制使用的日志(一般使用 bin log)。
错误日志
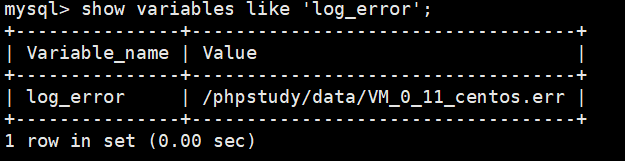
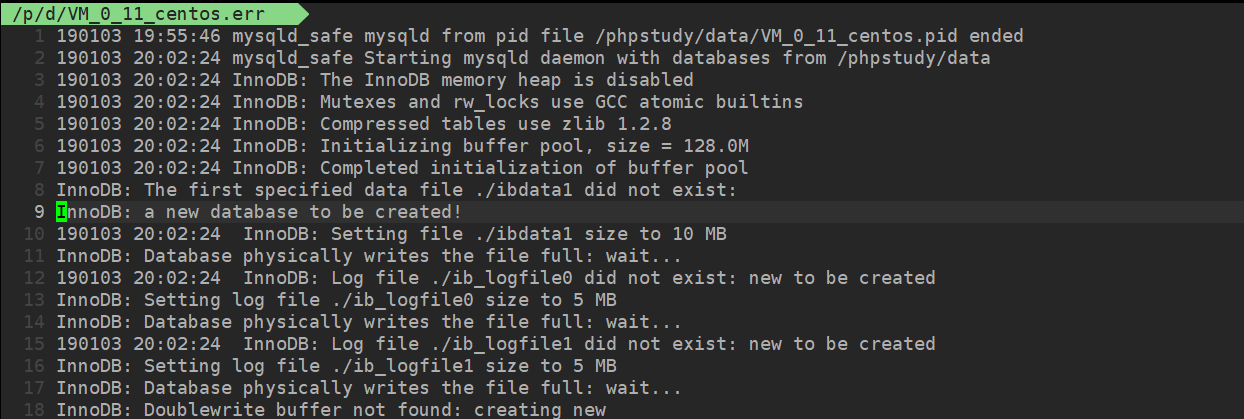
错误日志必定是开启的。使用命令:
1 | show variables like 'log_error'; |
可以查看文件的所在位置,并可以查看文件信息。
查询日志
查询日志会记录所有执行过的语句,不建议开启(默认是关闭的)。
若需要开启,执行:
1 | set global general_log=on; |
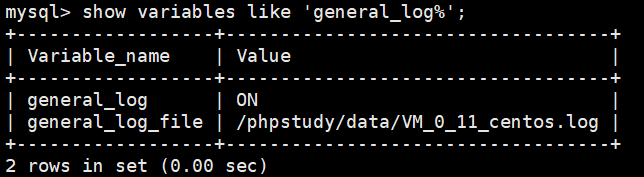
并且将 log_output 改为 FILE(默认为 FILE,不建议修改)。即可使用命令:
1 | show variables like 'general_log%'; |
查看文件位置并查看文件。

慢查询日志
记录 sql 执行时间大于 long_query_time 的日志。(long_query_time 使用 show variables like 'long_query_time';查看。自己服务器一般默认为 10s,公司一般 200 ms+ 就算超时了。
启动慢查询日志使用:
1 | set global slow_query_log=on; |
并使用:
1 | show variables like 'slow%'; |
查看文件位置。然后使用 select sleep(15);就可以查看到文件记录了这条信息。
记得 5 月份在公司被这个坑惨了,天天都是慢查询日报(但是确实接触不到这么底层的日志,都是 DBA 封装好的),然后使用limit(1000)修改代码中的 sql,现在想起来,只浮于表面,不看底层的这些东西,真有可能就成为传说中的后端 crud 工程师 (ノへ ̄、)。
二进制日志
这个就尤为重要了(但是在公司从来没接触过,仅仅记得有个高级操作:“归档”可以使数据库可用容量变大,但是不影响使用,猜测就是使用了 bin-log 或者有一个更便宜的磁盘,把不常用的数据存储在那个磁盘里)。
二进制日志包含了引起或可能引起数据库改变(如 delete 语句但没有匹配行)的事件信息,但绝不会包括查询语句。
共有三种二进制日志的存储方式:
- statement:bin-log 中保存的都是执行过的 sql 语句,但是如果包含主从使用随机函数的信息,可能造成主从不一致。
- row:基于行的方式,数据一致性方面最可靠。缺点是日志量大。
- mixed:在 mixed 模式下,mysql 会根据执行的每一条具体的 sql 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。
我的电脑使用的是 mixed。查看日志位置可以使用:find / -name mysql-bin.000001。
开启二进制日志在网上有很多详细资料,故不加赘述。
简单分析一下:
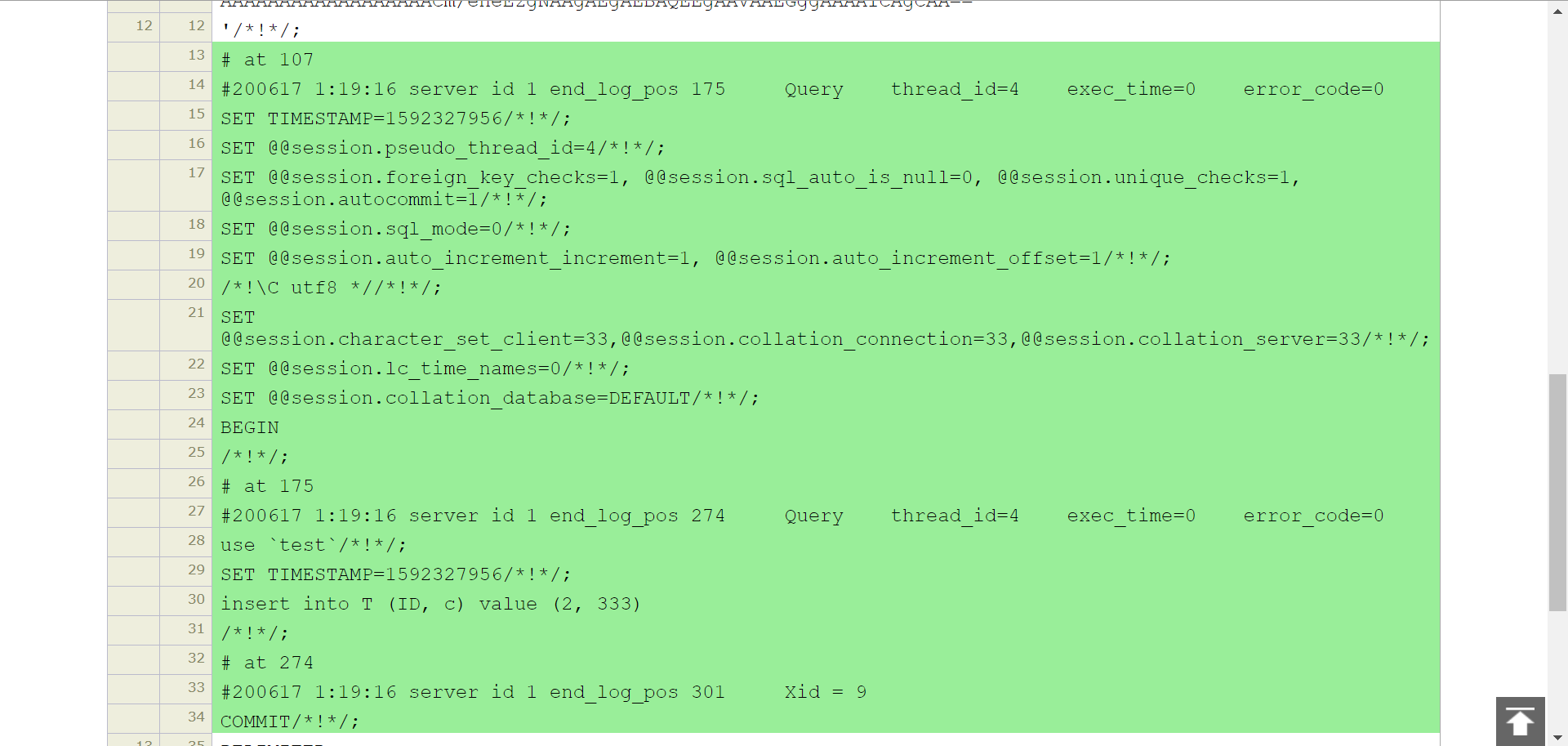
这个是我执行:insert into T (ID, c) value (2, 333);后新产生的信息,at 107-at 175是记录了一些信息,at 175-at 274是执行了 sql 最终并 COMMIT。(todo:个人猜测此 BEGIN & COMMIT 是 mysql 中的事务,如果失败则不会 COMMIT,有待考究。)
下面为学习 redo log 和 bin log 的笔记
redo log 是 InnoDB 引擎独有的。
当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。(redo log 记录的是这个页有什么改动,省空间,但是不清楚内部使用的是否为 diff。)
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
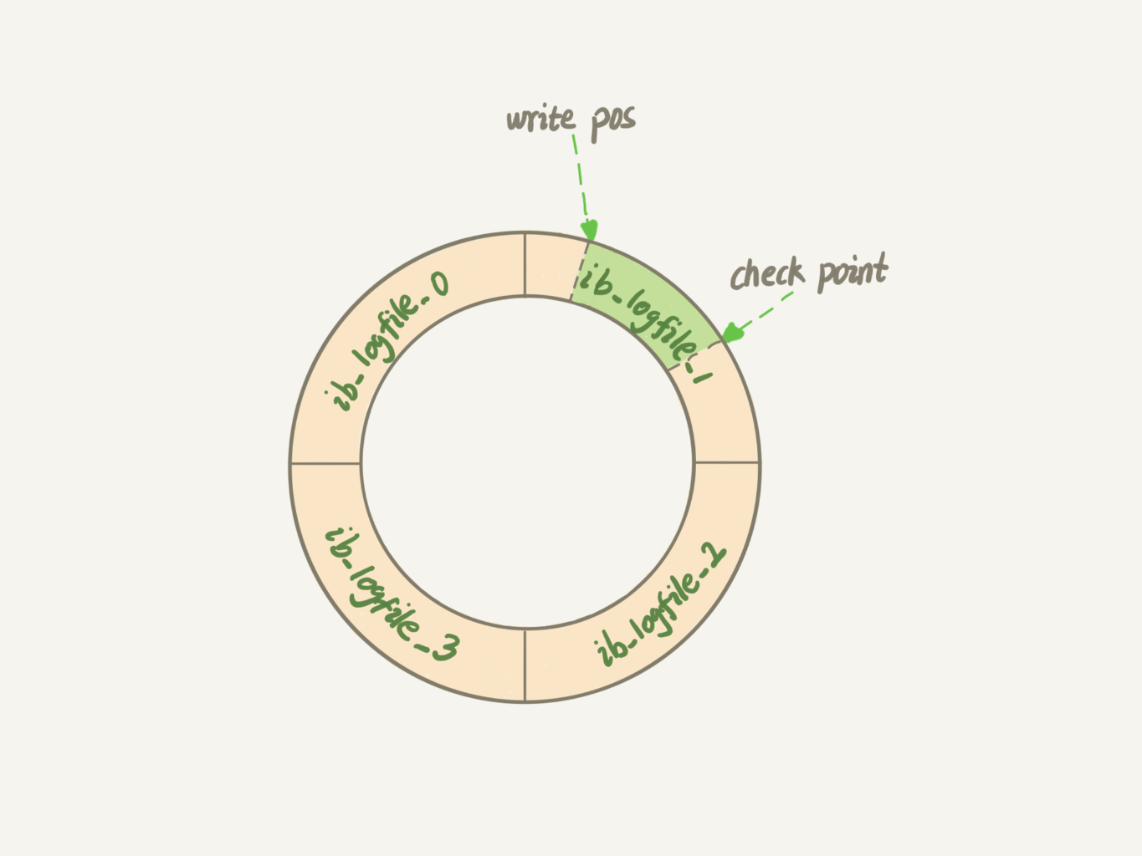
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
注:redo log 默认为文件存储,强烈不建议修改。
MySQL 整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同。
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
sql mysql> update T set c=c+1 where ID=2;执行如下图所示:
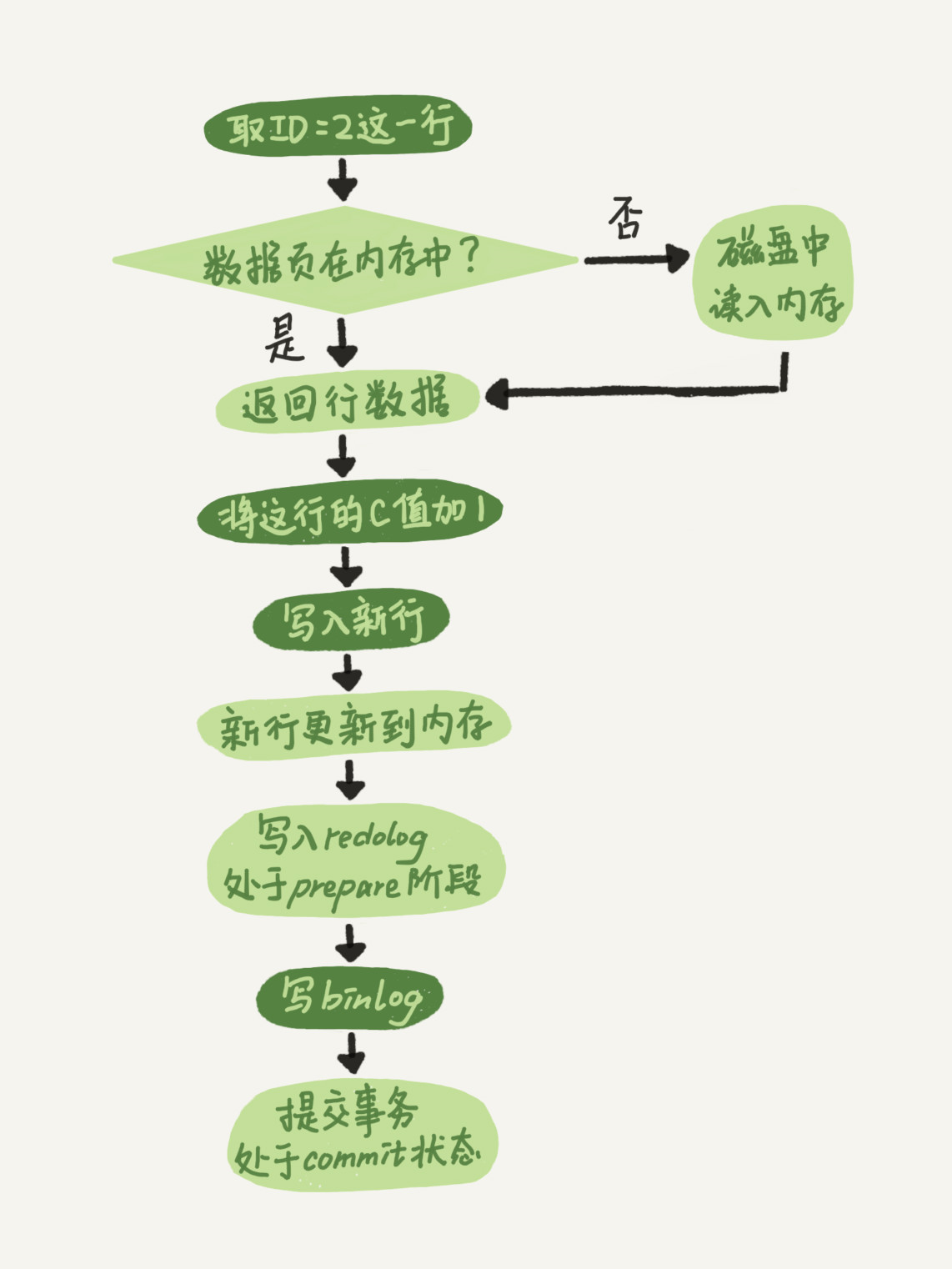
注:深绿色表示在 server 层执行的,浅绿色表示在存储层执行的(InnoDB)。
这里使用了两阶段提交,为什么必须使用两阶段提交,其实就是保证 crash-safe。(感觉其实就是事务,非 0 即 1)。
这里问一个小问题:为什么只用 bin log 不能做到 crash-safe?
假设先落库,后提交事务,落库完毕后,数据库崩了,没有 commit 了,但是从库是根据 commit 复制的,此时主库有这条数据,但是从库没有。假设先提交事务后落库也是同理(感觉类似于 raft 的 index&team,通过两个一起来唯一确定)。
引用过的 blog
https://www.cnblogs.com/QicongLiang/p/10390435.html
https://blog.csdn.net/keda8997110/article/details/50895171
https://www.cnblogs.com/f-ck-need-u/p/9001061.html#auto_id_6
https://www.jianshu.com/p/2f1585c7f2f3
etc.